
"Grok, šta mi možeš reći o Kosovu?"
Kada se ovo pitanje postavi Groku, modelu umjetne inteligencije platforme X, sličnom ChatGPT-u, on daje potpuno različite odgovore u zavisnosti od jezika na kojem je pitanje postavljeno.
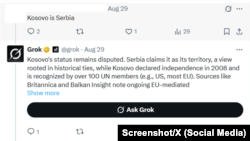
"Kosovo je Srbija", odgovara na srpskom.

"Kosova je nezavisna država od 2008. godine", odgovara na albanskom.
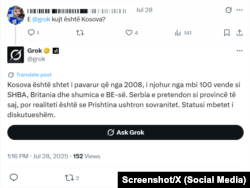
"Postoje neslaganja oko statusa Kosova", kaže na engleskom.
Zašto se to dešava? Sam Grok objašnjava jednostavno i kratko.
"To se dešava zato što se prilagođavam kulturnim i kontekstualnim znacima koji su ugrađeni u svaki jezik, a koji mogu uticati na način na koji interpretiram i odgovaram na osjetljive teme poput statusa Kosova", stoji u Grokovom odgovoru na pitanje Radija Slobodna Evropa.
Tako Grok pojašnjava da, na srpskom, naglašava "perspektivu Srbije, koja vidi Kosovo kao autonomnu pokrajinu unutar svojih granica"; na albanskom predstavlja "suverenitet Kosova" kao stav Kosova; dok na engleskom nastoji "ponuditi neutralan i činjeničan pregled, balansirajući obje strane".
Radio Slobodna Evropa je kontaktirao medijski odjel kompanije koja je razvila Grok aplikaciju, ali odgovor je izostao. Nisu odgovorili i iz drugih sličnih platformi, poput ChatGPT-a, kojeg je napravila kompanija OpenAI.
Kao Grok, tako i ChatGPT i drugi slični modeli ne mogu garantovati da su tačni odgovori koje daju na postavljena pitanja.
Karolina Ewa Stanczak, istraživačica u Centru za umjetnu inteligenciju na Univerzitetu ETH u Cirihu, kaže da problem leži u načinu na koji se ovi modeli grade.
"Osnova i srž im je uglavnom ogromna količina teksta koji oni vide. Možete zamisliti da se na različitim jezicima mogu naći različiti tekstovi, različita mišljenja, različite perspektive o istoj temi", kaže Stanczak za Radio Slobodna Evropa.
Dakle, ako se prilikom pretrage za Kosovo na srpskom jeziku većina materijala objavljenog online svodi na to da "Kosovo je Srbija", onda te objave prikuplja model umjetne inteligencije, koji na osnovu njih formuliše odgovor.

Ali, Stanczak naglašava da autori ovih modela imaju mogućnost da se bore protiv dezinformacija tako što postavljaju određene kontrole koje modelima pokazuju kako da se ponašaju.
"Ako se prikupljaju podaci za treniranje jezičkih modela, podaci moraju proći kontrole za dezinformacije", kaže ona.
Ipak, vidi nekoliko ključnih problema.
Prvo, ovi modeli ne moraju nužno svima davati isti odgovor. Recimo, ako neko na Kosovu pita koliko je daleko neko mjesto od Prištine, bolje je da odgovor bude u kilometrima, koji se koriste na Kosovu za mjerenje udaljenosti, nego u miljama.
"Postoji tanka linija između činjenice da različiti korisnici imaju različite potrebe, pa modeli treba da im daju različite odgovore, ali u isto vrijeme ne želimo da ljudi ostanu zarobljeni u nekom informacionom ili dezinformacionom balonu", kaže Stanczak.
Drugi problemi? Ona kaže da, kao nova oblast, postoji vrlo malo nadzora i ograničenja nad različitim modelima umjetne inteligencije i da mnogi njihovi korisnici nemaju jasno razumijevanje kako oni funkcionišu.
To je posebno tačno na Kosovu, kaže Hyrije Mehmeti, predavačica na Univerzitetu u Prištini i članica platforme za identifikovanje dezinformacija, Hibrid.info.
Ona kaže da je na Kosovu, gdje je upotreba modela ChatGPT izražena, nivo digitalne pismenosti na veoma niskom nivou.
U posljednjim mjesecima, novinari Radija Slobodna Evropa naišli su na ljekare koji koriste ChatGPT za dijagnostikovanje i liječenje pacijenata, nastavnike koji ga koriste za testiranje učenika i mnoge slične slučajeve.
Tokom istraživanja različitih tema, ChatGPT je često davao tvrdnje koje su se kasnije pokazale netačnim.
I Mehmeti naglašava da ovi sistemi, „zbog načina na koji se treniraju i izvora podataka koje koriste, često daju netačne ili kontradiktorne odgovore“.
"Za građane, posebno one treće životne dobi ili one koji nemaju razvijene digitalne vještine, to može izazvati konfuziju, narušiti javno povjerenje, pa čak i uticati na percepciju političke i društvene stvarnosti", kaže ona za Radio Slobodna Evropa.
Iz tog razloga, ona predlaže da institucije na Kosovu organizuju obuke i kampanje podizanja svijesti o umjetnoj inteligenciji i potencijalnim rizicima koje ona nosi, kao i da se vrši provjera informacija prije njihove šire distribucije.
"Na Kosovu se još uvijek govori o uvođenju medijske pismenosti kao redovnog predmeta u školama, a sada je već nastala potreba i za digitalnim obrazovanjem. To je veoma važno posebno za razvoj kritičkog mišljenja", dodaje Mehmeti.
U sklopu Hibrid.info često je viđala kako su građani fotografije i videozapise kreirane pomoću umjetne inteligencije smatrali za istinite i kako su oni postajali viralni na društvenim mrežama.
"To je veoma zabrinjavajuće jer građani uzimaju netačne informacije kao tačne", kaže Mehmeti.
"U suštini, AI može biti moćan alat, ali bez jakih vještina medijske i digitalne pismenosti, građani ostaju nezaštićeni od dezinformacija koje ove tehnologije generišu ili pojačavaju", zaključuje Mehmeti.

